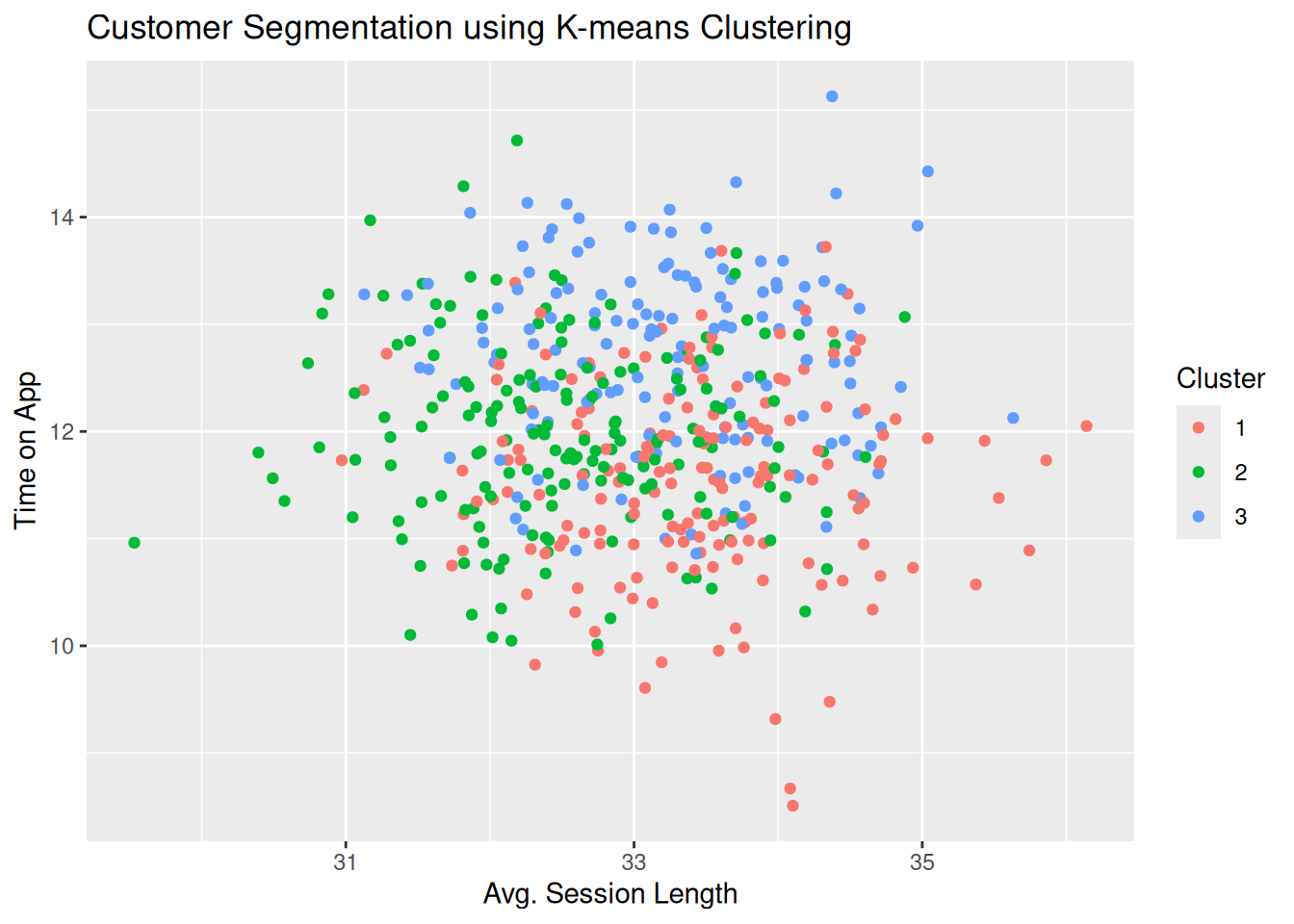
This document presents the analysis of an e-commerce dataset using various statistical methods, including simple and multiple linear regression, feature engineering, and customer segmentation through K-means clustering.
2.1 1. Import Data and Basic Exploration
We begin by loading the dataset and performing a basic exploration.
'data.frame': 500 obs. of 8 variables:
$ Email : chr "mstephenson@fernandez.com" "hduke@hotmail.com" "pallen@yahoo.com" "riverarebecca@gmail.com" ...
$ Address : chr "835 Frank Tunnel\nWrightmouth, MI 82180-9605" "4547 Archer Common\nDiazchester, CA 06566-8576" "24645 Valerie Unions Suite 582\nCobbborough, DC 99414-7564" "1414 David Throughway\nPort Jason, OH 22070-1220" ...
$ Avatar : chr "Violet" "DarkGreen" "Bisque" "SaddleBrown" ...
$ Avg..Session.Length : num 34.5 31.9 33 34.3 33.3 ...
$ Time.on.App : num 12.7 11.1 11.3 13.7 12.8 ...
$ Time.on.Website : num 39.6 37.3 37.1 36.7 37.5 ...
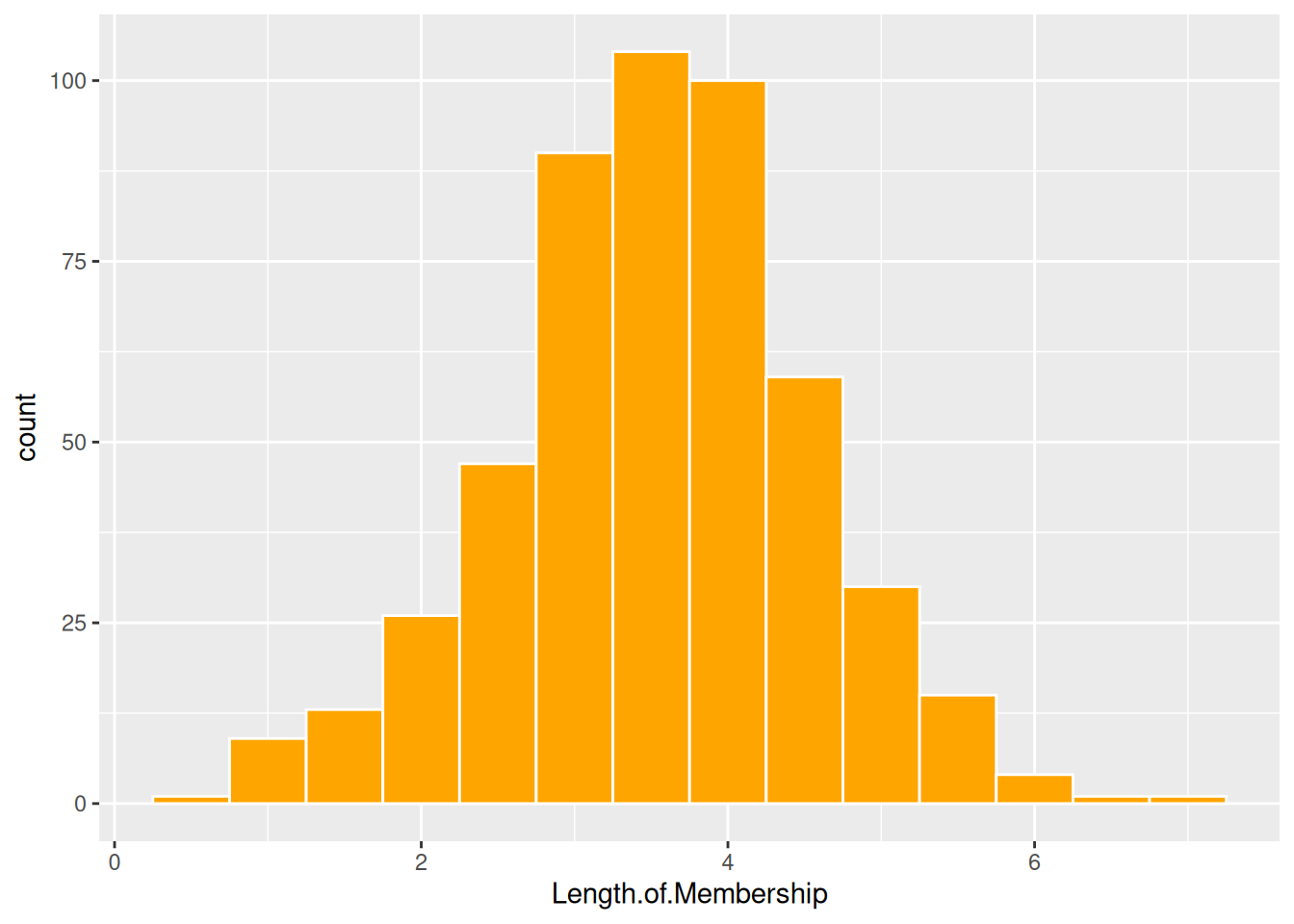
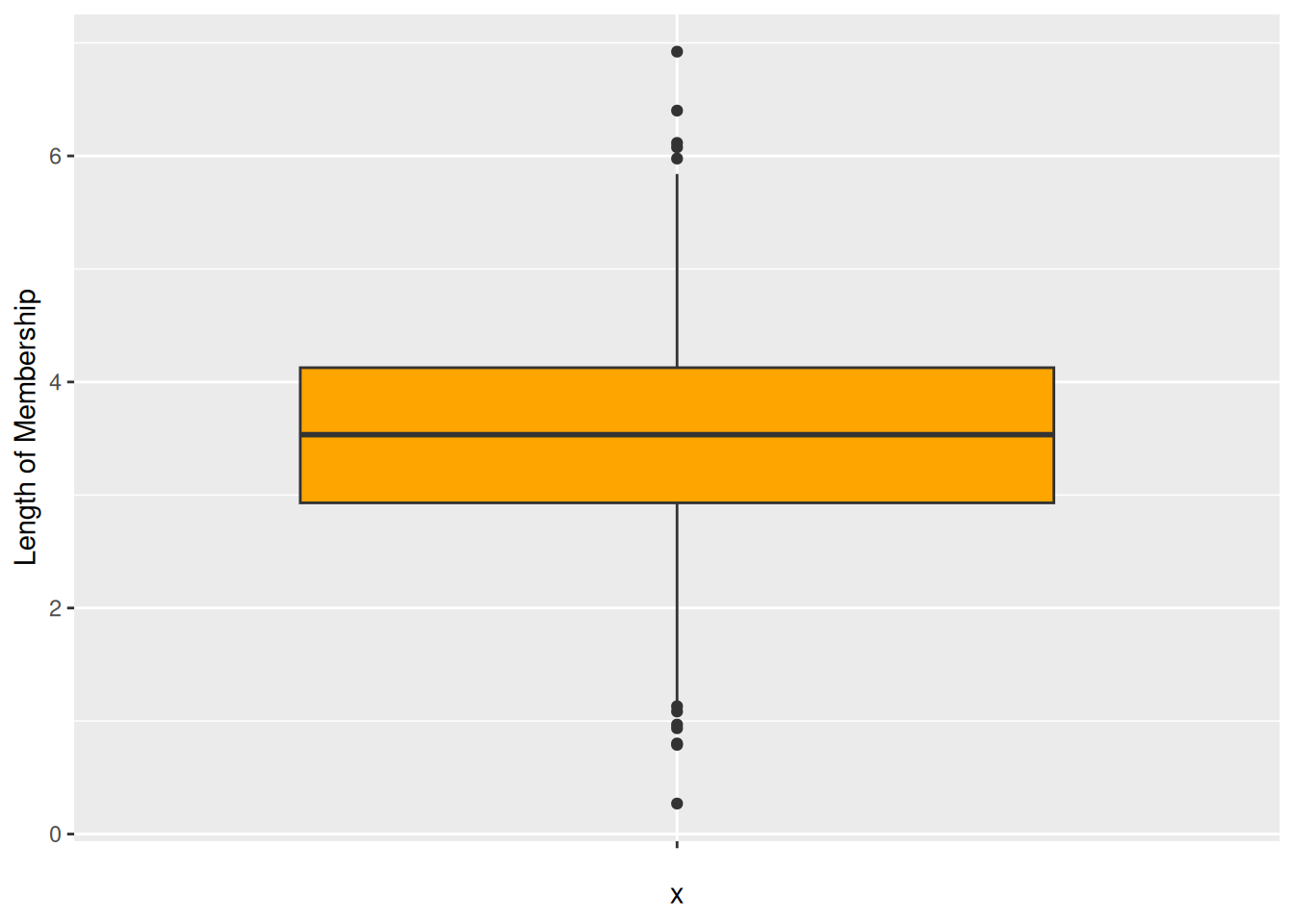
$ Length.of.Membership: num 4.08 2.66 4.1 3.12 4.45 ...
$ Yearly.Amount.Spent : num 588 392 488 582 599 ...
summary(ecomdata)
Email Address Avatar Avg..Session.Length
Length:500 Length:500 Length:500 Min. :29.53
Class :character Class :character Class :character 1st Qu.:32.34
Mode :character Mode :character Mode :character Median :33.08
Mean :33.05
3rd Qu.:33.71
Max. :36.14
Time.on.App Time.on.Website Length.of.Membership Yearly.Amount.Spent
Min. : 8.508 Min. :33.91 Min. :0.2699 Min. :256.7
1st Qu.:11.388 1st Qu.:36.35 1st Qu.:2.9304 1st Qu.:445.0
Median :11.983 Median :37.07 Median :3.5340 Median :498.9
Mean :12.052 Mean :37.06 Mean :3.5335 Mean :499.3
3rd Qu.:12.754 3rd Qu.:37.72 3rd Qu.:4.1265 3rd Qu.:549.3
Max. :15.127 Max. :40.01 Max. :6.9227 Max. :765.5
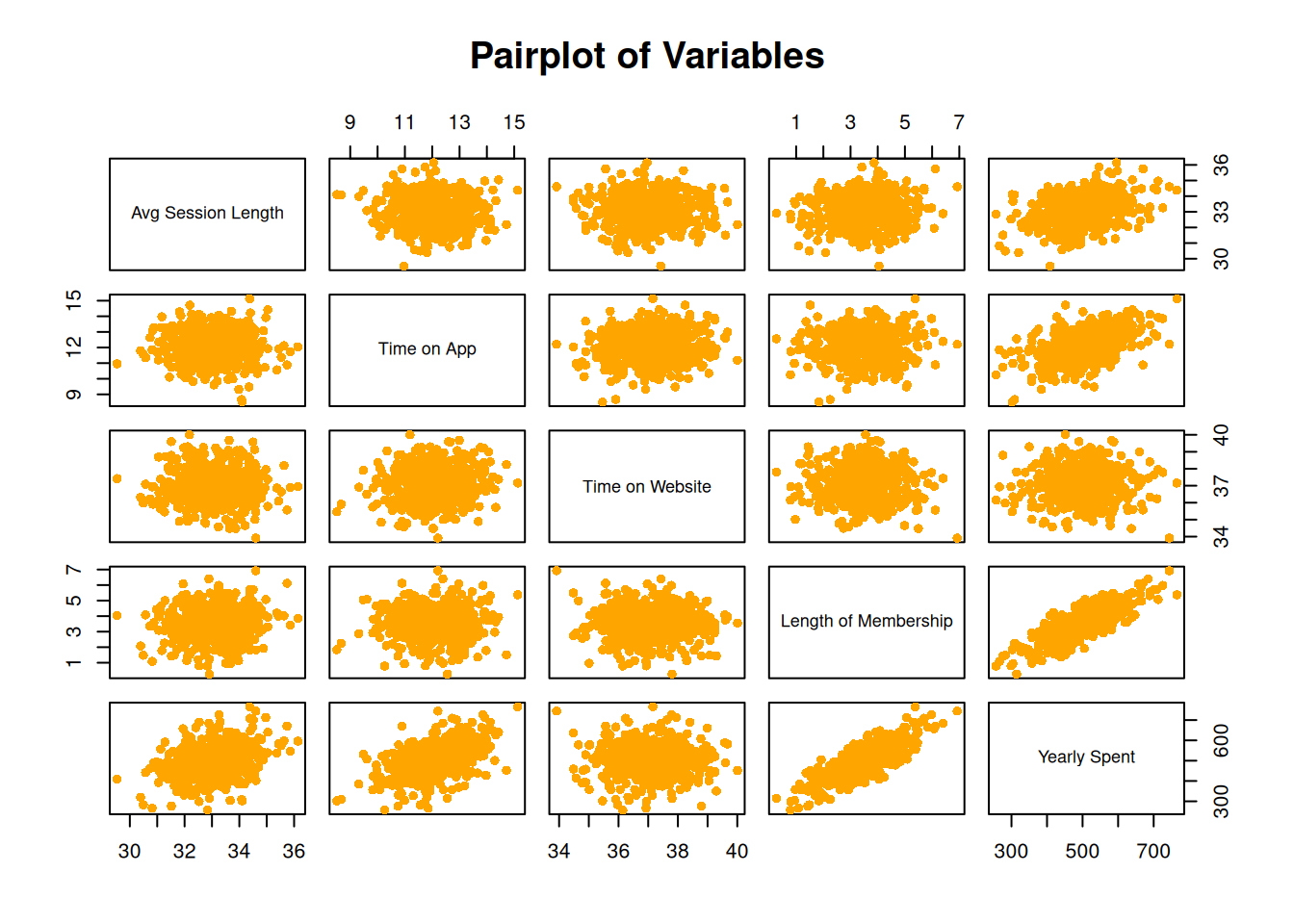
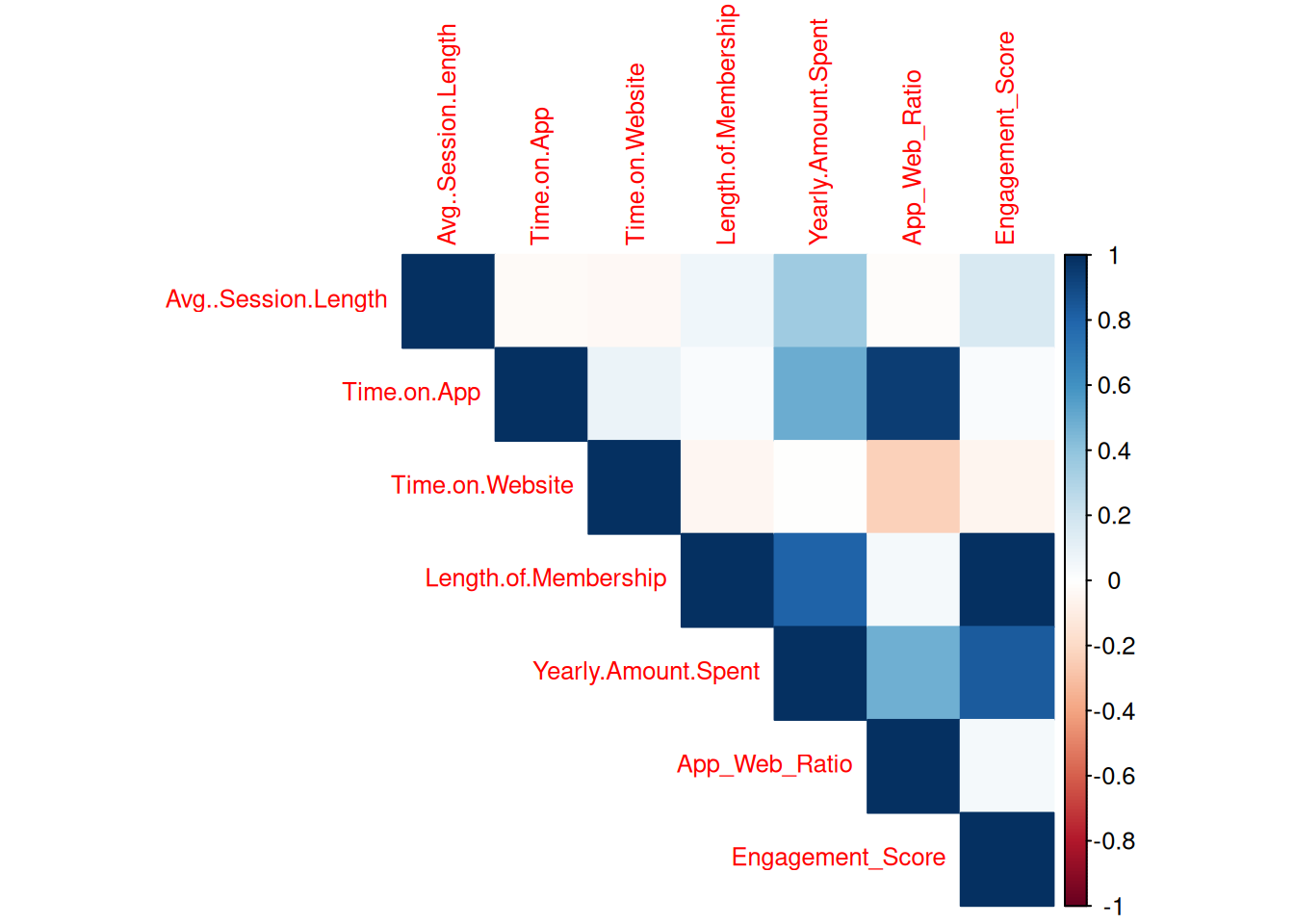
2.2 2. Visualization and Correlation Analysis
2.2.1 2.1 Scatter Plots
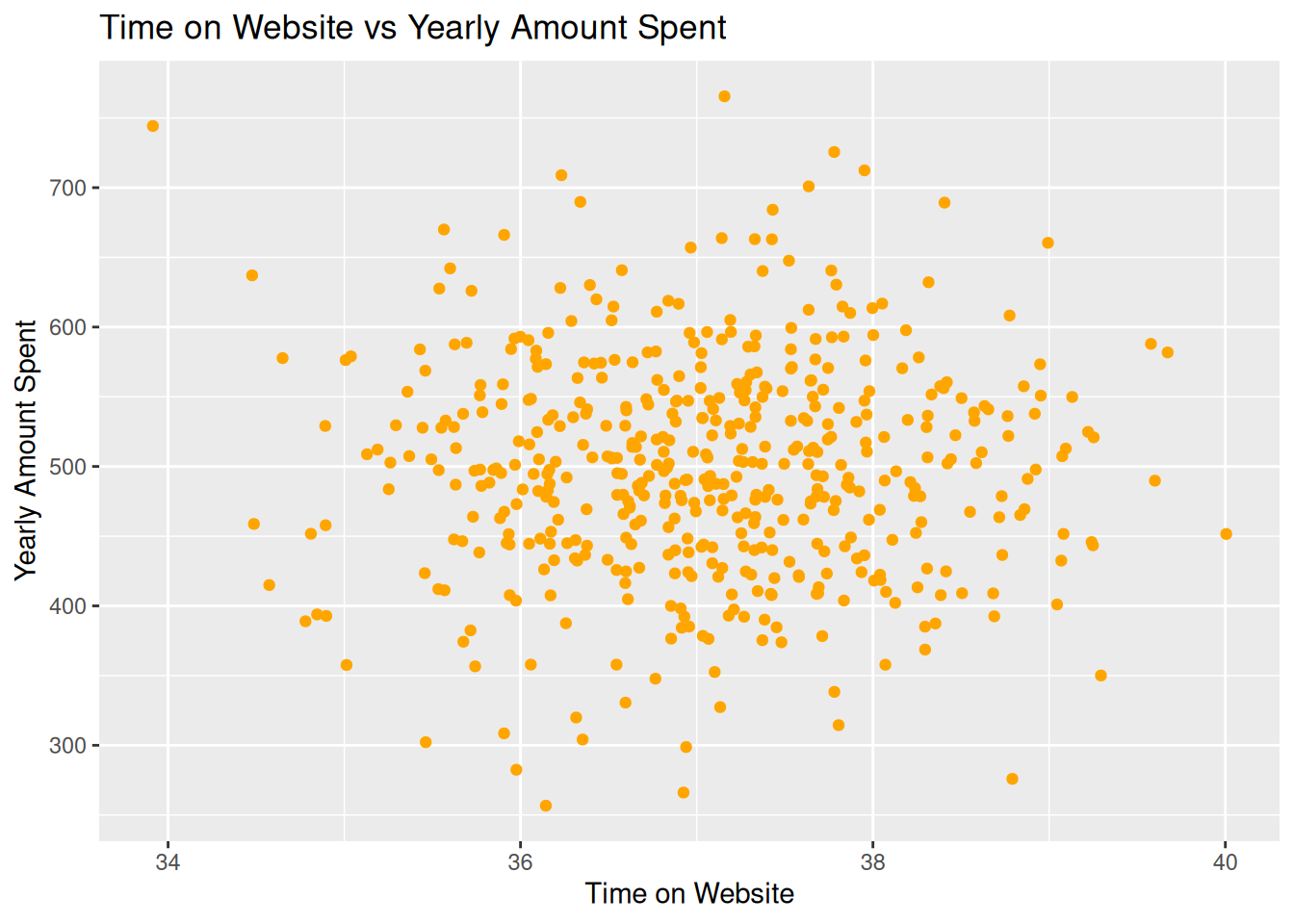
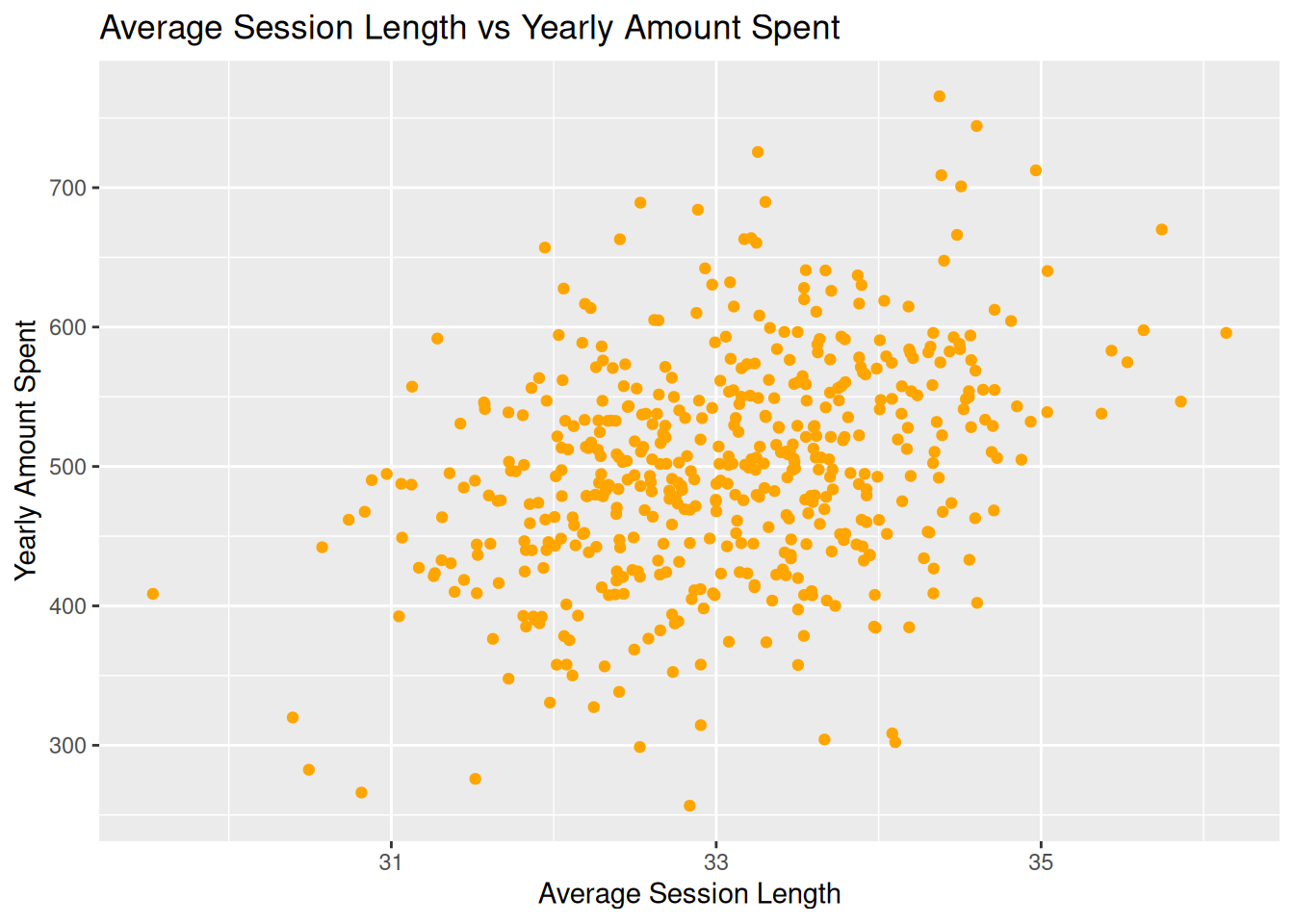
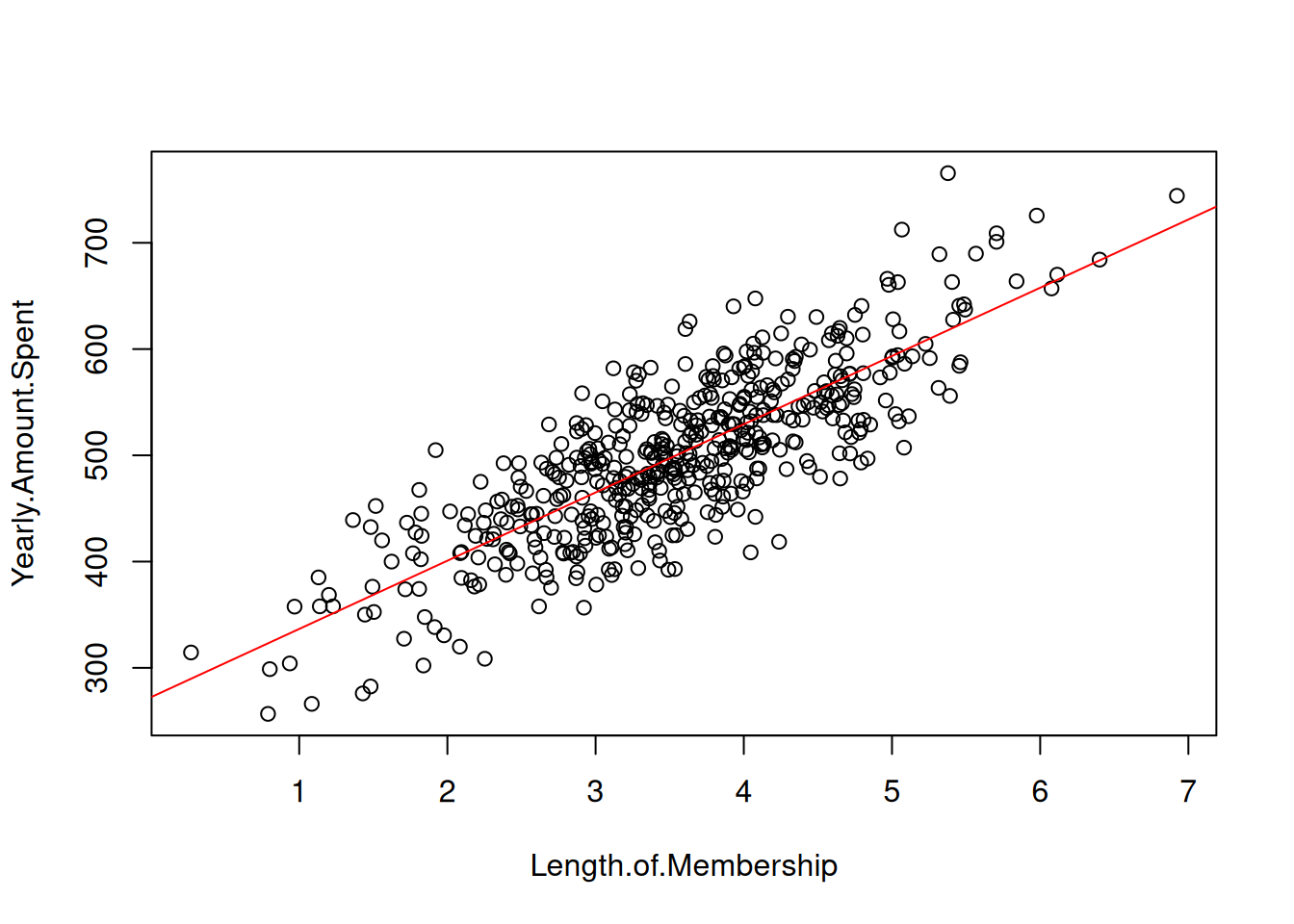
The following scatter plots show the relationship between various variables:
Time on Website vs Yearly Amount Spent
library(ggplot2)ggplot(ecomdata, aes(x = Time.on.Website, y = Yearly.Amount.Spent)) +geom_point(colour ="orange") +ggtitle("Time on Website vs Yearly Amount Spent") +xlab("Time on Website") +ylab("Yearly Amount Spent")